このシリーズの前回までの記事を読んできた方なら、あるパターンが見え始めていることに気づいているかもしれません。
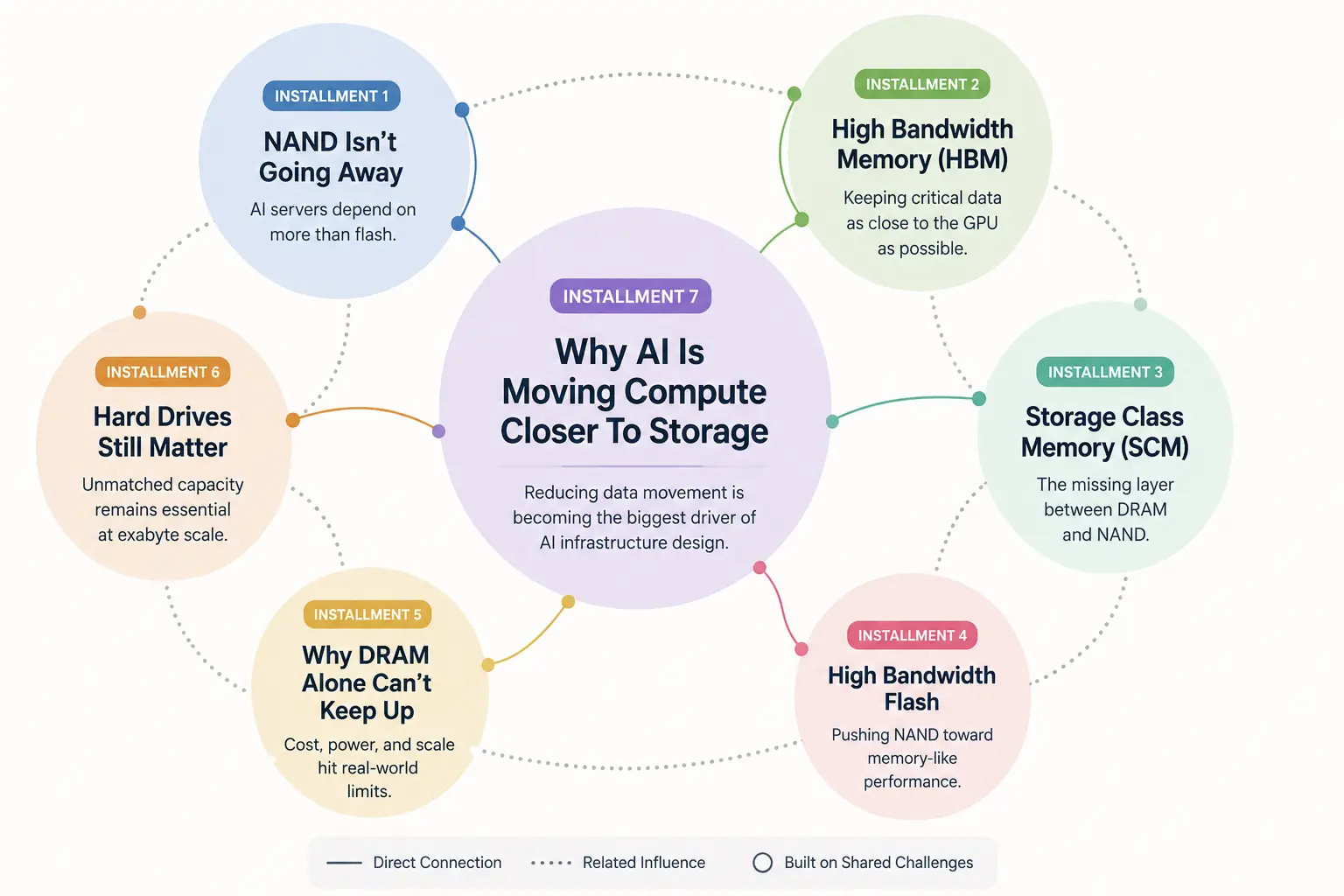
最初の記事では、NANDフラッシュは消えていくのではなく、むしろより大きなAIメモリ階層の一部になっている、という話をしました。その後、High Bandwidth Memory(HBM)を取り上げ、現代のGPUがなぜプロセッサの物理的に近くにあるデータに依存しているのかを見ました。そこからStorage Class Memory、High Bandwidth Flash、DRAMスケーリングの限界へと進み、最後に、従来型のハードドライブでさえ今なお重要であり続ける理由を説明しました。AIインフラは、多くの人が大きく見誤っているほどの規模で動いているからです。
一見すると、これらは別々のテーマに見えるかもしれません。
しかし、そうではありません。
すべては同じ根本的な圧力から生じている症状です。AIシステムは、もはや主に演算能力そのものと戦っているのではありません。データをどれだけ効率よく動かせるかと戦っているのです。
この変化は、インフラ設計のほぼすべてを変えます。
何十年もの間、コンピューティングはかなり安定したモデルに従ってきました。ストレージがデータを保持し、メモリがそれを一時的に配置し、プロセッサが必要なものを取りに行く。プロセッサが速くなるにつれて、システムはより良いバス、より大きなキャッシュ、より高速なメモリ技術を使って、プロセッサへより効率よくデータを供給しようとしてきました。
AIは、その問題のスケールを変えました。
現代のGPUクラスタは、非常に大きな速度で情報を処理できます。その結果、システム内でデータを移動させるという行為そのものが、アーキテクチャ全体における最大級のボトルネックの一つになり始めています。一部の環境では、プロセッサ自体はもはや遅い部分ではありません。遅延は、プロセッサを十分に使い切るために、適切なデータを十分な速さと一貫性で届けるところから生まれます。
この認識が、業界を静かに新しい方向へ押し出しています。
より大きなデータ量をシステム全体で絶えず行き来させるのではなく、AIインフラは、データがすでに存在している場所の近くへ、コンピュートの一部を移動させ始めています。
そして、なぜそれが起きているのかを理解すると、このシリーズの前回までの記事が、よりはっきりとつながって見えてきます。
AIはデータ移動の壁にぶつかり始めている
以前のHBMの記事で最も重要だった考え方の一つは、現代のAIシステムが遅くなる理由は、プロセッサに演算能力が足りないからではなく、システムがプロセッサを忙しく保つだけの速さでデータを届けられないからである、という点でした。
この問題は、AIワークロードがラック全体やクラスタ全体へ広がると、さらに深刻になります。
現代のAIアクセラレータは、驚くほど大量の情報を並列に処理できます。問題は、データセットがもはや最速のメモリ層の中に完全に収まるほど小さくないことです。HBMや大容量のDRAMプールがあっても、膨大な量のデータは、インターコネクト、バス、ファブリック、ストレージ層、ネットワークインフラを通って移動する必要があります。
その移動にはコストがあります。
それはレイテンシとして現れますが、それは話の一部にすぎません。消費電力、発熱、冷却需要、混雑、同期遅延、そしてアイドル状態の演算サイクルとしても現れます。DRAMの記事で説明したように、非常に小さな遅延でさえ、数千基のGPUが同時に動いている環境では驚くほど高くつきます。大規模AIクラスタ全体で小さな停止が積み重なると、非常に大きな利用率の損失になります。
これにより、エンジニアリング上の優先順位が変わります。
長い間、インフラは主に演算性能を最大化することを中心に設計されてきました。しかしAIシステムは今、エンジニアに対して、データローカリティ、つまり情報がそれを使おうとしているプロセッサに対して物理的にどこにあるのかを、同じくらい真剣に考えさせています。
簡単に言えば、距離が以前よりはるかに重要になっているのです。
GPUが速くなりすぎて、システムの他の部分が追いつかなくなった
AIインフラで少し不思議なのは、ある領域で進歩が起きると、別の場所の弱点が露出しやすいことです。
GPUが高速化すると、メモリ帯域幅がボトルネックになりました。それがHBMにつながりました。HBMの容量面の制約がより明らかになると、業界はStorage Class Memoryのような中間層を導入し始めました。DRAMのスケーリングが高コストで物理的にも難しくなると、システムはNANDへの依存を強める一方で、High Bandwidth Flashのような概念も探り始めました。
そしてAIデータセットがペタバイト、エクサバイト規模へ広がり続ける中で、ハードドライブは静かに不可欠であり続けました。それほど大量の情報を保存する経済性は、ほかの方法だけでは成り立たないからです。
このシリーズの各記事は、実のところ、異なる角度から同じ結論を指していました。
コンピュートはこちらにあり、ストレージはあちらにある、という古い前提が崩れ始めています。理由はかなり単純です。GPUは、従来型アーキテクチャが無理なくデータを届けられる速度を超えて、データを処理できるようになっているからです。
その結果、システム活動の膨大な部分が、単に情報をある場所から別の場所へ運ぶことに費やされる状況が生まれます。実用的に見ると、一部のAI環境は、純粋な演算問題というよりも、物流問題のように見え始めています。
業界は別の問いを立て始めた
長い間、ストレージの革新は、主にストレージデバイスを高速化することに集中していました。より速いSSD、より速いインターフェース、より速いNAND、より速いコントローラはすべて重要でしたし、今でも重要です。
しかしAIワークロードは、その下にあるさらに深い問題を浮き彫りにし始めました。
ある時点でエンジニアたちは、問題は必ずしもストレージデバイス自体の速度ではない、と気づき始めました。問題は、膨大な量のデータをシステム全体で何度も何度も往復させることでした。
この微妙な違いは重要です。問題が単純なストレージ速度ではなくデータ移動になると、解決策も変わり始めるからです。
ストレージをどうすればもっと速くできるか、と延々と問い続ける代わりに、業界はそもそもデータがどれだけ移動する必要があるのかを問い始めました。
この問いは、現代のAIインフラ設計のほぼすべての部分に影響を与えています。
データがすでに存在する場所へコンピュートを近づける
ここでアーキテクチャが変わり始めます。
ストレージを、要求をただ待つだけの完全に受動的な層として扱うのではなく、新しいシステムでは、特定の処理をデータそのものの近くで行い始めています。必ずしもGPU並みの大規模処理を行うわけではありませんが、システム全体で不要な移動を減らすためのローカルな処理です。
一部のシステムでは、フィルタリング、インデックス化、検索処理、圧縮、取得準備、データ整理を、情報が主要なコンピュートエンジンへ到達する前に、ストレージ層の近くで実行するようになっています。
目的はGPUをなくすことでも、高速メモリを置き換えることでもありません。目的は無駄を減らすことです。
システムが不要な大量データをインフラ全体に運ばずに済むなら、プラットフォーム全体はより効率的になります。これが、コンピュートとストレージの境界線が曖昧になり始めている理由の一つです。
ストレージは、もはや階層の底に座っている完全に非アクティブな目的地のようには振る舞っていません。データがどのように準備され、配置され、フィルタリングされ、上流へ届けられるかに、より深く関わるようになっています。
以前のHigh Bandwidth Flashの記事を思い出すと、この方向性は非常に理にかなっています。あの記事では、NANDそのものがよりメモリらしい振る舞いへ押し出されていることを示しました。この記事では、同じ考え方をさらに一歩進め、周辺アーキテクチャもデータ移動のコストに合わせて適応していることを示しています。
倉庫のたとえは少し違って見え始める
このシリーズ全体で使ってきた倉庫のたとえは、ここでもまだ有効です。ただし、倉庫そのものは、中で行われる作業が変わったために進化し始めています。
以前の記事では、配置はかなり分かりやすいものでした。HBMは、次のパレットが作業員のすぐ横で待っている積み込みドックを表していました。DRAMは、すぐに必要な仕分けや取り扱いが行われる作業フロアでした。Storage Class Memoryは、ドックのすぐ後ろにある準備エリアになり、NANDはさらに奥にある倉庫の主要な棚を表していました。ハードドライブは、長期在庫が置かれるより深いバルクストレージを担当していました。そこでは即時アクセス速度よりも容量のほうが重要だったからです。
このモデルは全体としてはまだ成り立ちますが、AIシステムは、これらの領域間でどれだけ多くの移動が発生しているかという非効率を露出し始めています。
作業員が在庫を実際に処理するよりも、倉庫内をフォークリフトで行ったり来たりすることに多くの時間を使っている倉庫を想像してみてください。最初、管理側はより速いフォークリフトを買い、通路を広げ、積み込みドックを改善します。そうした改善はしばらく効果がありますが、やがて運用は、輸送そのものが問題になる地点に到達します。遅れは、作業員が遅いからでも、設備が不十分だからでもありません。ワークフローを維持するために必要な移動量そのものから生じます。
大規模AIシステムが直面し始めているのは、まさにそれに近い状況です。
問題は、データがGPUに到達した後にどれだけ速く処理できるかだけではありません。そもそも、そのデータをシステム全体で繰り返し運ぶために、どれだけのインフラ努力が費やされているのかが問題になっています。
そこで、輸送を果てしなく最適化する代わりに、配置そのものが変わり始めます。小さな作業ステーションが棚の近くに現れます。特定の仕分け作業はローカルで行われます。フィルタリングもローカルで行われます。データの準備は、情報がすでに存在している場所の近くで行われるようになり、システムが巨大な量の材料を運用全体で何度も往復させる必要が減ります。
この変化は、AIインフラがアーキテクチャレベルで始めていることと本質的に同じです。目的はストレージをプロセッサに変えることでも、集中型コンピュートを完全になくすことでもありません。目的は不要な移動を減らすことです。AI規模では、小さな非効率でさえ、同時に動作する数千のアクセラレータ全体に掛け合わされると驚くほど高くつくからです。
AIインフラは必要に迫られてより分散型になっている
この変化のより興味深い結果の一つは、AIインフラが、従来のコンピューティング環境で必要とされていた以上に、はるかに分散型になり始めていることです。
古いアーキテクチャでは、重要な作業の大半は集中化されたコンピュート場所で行われ、ストレージはほぼ受動的で、処理層から切り離されたままだと想定されていました。このモデルは何十年もの間、かなりうまく機能しました。システム内を移動するデータ量が、それを消費するプロセッサの速度に対して、まだ管理可能な範囲にあったからです。
AIは、その方程式のスケールを完全に変えます。
処理され、再参照され、配置され、キャッシュされ、インデックス化され、取得される情報量が非常に大きくなったため、集中型の移動そのものが非効率を生み始めています。コンピュートが何かを必要とするたびに単純にストレージへ降りていくのではなく、システムは、有用なデータを次に使われる可能性が高い場所の近くに置いておこうとする傾向を強めています。
これが、ベクトルデータベース、分散推論システム、リトリーバル層、ローカルキャッシュ、ニアデータ処理といった技術が大きな注目を集め始めている理由の一部です。表面的には、これらは無関係な問題を解決する別々の技術に見えるかもしれません。しかし根底では、すべて同じ圧力に反応しています。業界は、意味のある作業が始まる前に、膨大な情報がインフラ内の長い距離を移動しなければならない回数を減らそうとしているのです。
このシリーズを通じておそらく気づいたように、メモリ階層そのものも、以前ほど硬直したものではなくなりつつあります。「コンピュートはこちら」「ストレージはあちら」という明確な分離は、AIワークロードがデータを処理場所の物理的な近くに保つシステムを有利にするため、徐々に和らいでいます。
この傾向は今後も続く可能性が高いでしょう。大規模AIの経済性は、生の演算能力と同じくらい、移動効率を重視する方向へ進んでいるからです。
メモリ階層は互いに溶け合い始めている
このシリーズの各回の下に流れていた静かなテーマの一つは、メモリ、ストレージ、コンピュートの古い境界が少しずつ削られていくことでした。
HBMの記事では、メモリが物理的にプロセッサそのものへ近づけられたことを見ました。従来型のDRAM配置でさえ、AI規模では無視できないほどの遅延を生み始めたからです。Storage Class Memoryの記事では、高速メモリと低速な永続ストレージの間にある急な段差を小さくすることに焦点を移しました。High Bandwidth Flashは、NANDを作業データパスの中でより能動的な役割へ押し出し、DRAMの記事では、従来型メモリを単純に無限に増やしていくことが、経済的にも物理的にも難しくなる理由を示しました。
この記事は、その同じ流れをさらに一歩進め、アーキテクチャそのものがデータ移動のコストに合わせて適応していることを示しています。
特に興味深いのは、これらの技術が本当の意味で互いを置き換えているわけではないことです。HBMが登場したからといって、業界がNANDを捨てたわけではありません。Storage Class Memoryが現れたからといって、DRAMが置き換えられたわけでもありません。ソリッドステートストレージがハードドライブを完全に消し去るという予測が何十年も続いてきたにもかかわらず、ハードドライブも依然として深く重要です。
その代わりに、システムはより階層化され、より専門化され、データがそれを消費しようとするコンピュート資源に対して物理的にどこに存在するのかを、より意識するようになっています。
この違いは重要です。AIインフラの未来をどう考えるべきかを変えるからです。この進化は、ある画期的な技術が突然すべてを解決したから起きているのではありません。ワークロードそのものが、情報を効率よくコンピュート側へ供給するために、各層がどのように関与するかを業界に再編成させた結果として起きています。
一歩引いて全体像を見ると、このパターンはずっと分かりやすくなります。このシリーズで取り上げてきた主要な変化は、最終的にはすべて同じ目的を指しています。情報を場所から場所へ移すだけに費やされる時間、エネルギー、インフラ上のオーバーヘッドを減らすことです。
未来は生の演算力よりもデータ配置に左右されるかもしれない
長い間、テクノロジー業界は進歩を主に生の演算能力で測ってきました。より速いプロセッサ、より大きなアクセラレータ、より多くのコア、より高い並列性が、進歩の主要な指標とされてきました。従来型のワークロードの多くでは、演算性能を高めれば、一般にシステム全体も改善されたからです。
AIは、より繊細な議論を強いています。
プロセッサが十分に速くなると、より大きな課題は処理を実行する能力ではなく、プロセッサが高価なアイドル時間を避けられるだけの有用なデータを、継続的に供給し続ける能力へ変わります。この微妙な変化は、現代のAIインフラ内部で行われているほぼすべての主要なアーキテクチャ判断に影響を与えています。
興味深いのは、解決策がもはや単独でより高速なストレージデバイスを作ることや、より大きなメモリプールを構築することだけではない点です。むしろ業界は、システム全体のどこにデータが存在するのか、どれだけ頻繁に移動するのか、そしてコンピュート資源が関与する前に、アーキテクチャが不要な輸送をどれだけ賢く最小化できるのかに、ますます注目しています。
だからこそ、近接性はこのシリーズのすべての記事で繰り返し登場するテーマになっています。HBMはメモリを物理的にGPUへ近づけました。Storage Class Memoryはメモリとストレージの間の隔たりを縮めました。High Bandwidth FlashはNANDをメモリ階層へより能動的に参加させようとしました。分散ストレージシステムやニアデータ処理アーキテクチャは、インフラそのものの中で発生する移動量を減らそうとしています。
これらすべての進展は、同じ認識に反応しています。
AI規模では、データを効率よく移動させることが、到着したデータを処理することとほぼ同じくらい重要になりつつあります。
そしてそれは、AI時代全体を定義するアーキテクチャ上の大きな変化の一つになるかもしれません。
AIメモリインフラシリーズ
この記事は、AIインフラがメモリ、ストレージ、コンピュートの関係をどのように作り替えているのかを扱う連載の一部です。ここから読み始めた方は、前回までの記事を読むことで、なぜこの変化が起きているのかの土台が見えてきます。
第1回:
NANDはなくならないが、AIサーバーはもはやフラッシュだけに依存していない
第2回:
High Bandwidth Memory(HBM)とは何か、そしてなぜAIはこれに依存しているのか
第3回:
ストレージクラスメモリ解説:DRAMとNANDの間にある欠けた層
第4回:
High Bandwidth Flash:NANDはついにメモリのように振る舞えるのか
第6回:
なぜハードドライブはAIインフラにおいて今なお重要なのか
第7回:
なぜAIはコンピュートをストレージの近くへ移動させているのか
編集メモ:この記事は、GetUSB.infoが公開しているAIインフラとメモリアーキテクチャに関する継続シリーズの一部です。この記事は、構成と読みやすさを整えるためにAI支援による編集サポートを用いて調査・執筆され、その後、GetUSB編集チームによって技術的な正確性、連続性、明確さの観点から確認・調整されました。
著者について
この記事は、USB技術、フラッシュメモリの挙動、データストレージシステムにおいて20年以上の経験を持つGetUSB.infoの長年の寄稿者、Matt LeBoffの指揮のもとで作成されました。ここで示している視点は、AIインフラを含む進化するワークロードの下で、現実のシステムがどのように動作するかについての実務的な業界知識と継続的な分析に基づいています。