AIシステムは、計算能力の限界で遅くなることはあまりなく、むしろデータを十分な速度で動かせないために、プロセッサへ継続的に情報を供給できなくなることで性能が落ちます。
言い換えると、ボトルネックはデータを処理する能力ではなく、現代のAIワークロードが求める速度でデータを届ける能力にあります。
ここで重要な役割を果たすのがHigh Bandwidth Memory(HBM)です。
メモリがフラッシュを超えてどのように進化しているのか、そしてなぜAIシステムが複数の階層に依存するようになっているのかについては、こちらの分析も参考にしてください:NANDはなくならないが、AIサーバーはもはやフラッシュだけに依存していない。
High Bandwidth Memory(HBM)とは?
HBMはスタック型のDRAMで、プロセッサのすぐ近く、GPUダイから数ミリ程度の距離に配置され、データが移動する物理的な距離を最小限に抑えるよう設計されています。
従来のシステムメモリが長い電気的経路や狭いデータチャネルに依存しているのに対し、HBMは「近さ」と「並列性」を重視した設計となっており、一度により多くのデータを、より低い遅延で転送できるようになっています。
- 数千ビット幅にもなる広帯域メモリバス
- メモリとプロセッサ間の超短距離配線
- 大規模な並列データアクセス
目的はシンプルで、データが保存されている場所と処理される場所の距離を縮めることです。高性能システムでは、小さな遅延でもすぐに積み重なってしまうからです。
実際のところ、距離はそのままレイテンシに直結し、そのレイテンシがAI性能を制限する大きな要因の一つになっています。
HBMをイメージするシンプルな考え方
わかりやすい例として、従来のシステムを「工場」と「倉庫」が高速道路でつながっている構造だと考えてみてください。
工場が部品を必要とするたびに、それらは往復して運ばれなければならず、そのたびに遅延が発生し、エネルギー消費が増え、システム全体の速度が制限されます。
HBMはこの関係を変え、倉庫をそのまま工場の上に積み重ねたような構造にします。
輸送に頼る必要がなくなり、すべてがすぐにアクセス可能になるため、長距離移動による遅延がほぼなくなります。
これがGPUにおけるHBMの役割であり、メモリを計算エンジンのすぐ近くに配置することで、従来設計と比べてデータ移動がほぼ瞬時に行われるようになります。
HBMの物理構造
HBMの利点はレイアウトだけでなく、シリコンレベルでの構造にもあります。
HBMは複数のDRAMダイを垂直に積み重ね、Through-Silicon Via(TSV)と呼ばれる微細な縦方向の通路で接続されます。これにより、シリコンを貫通する形で層間の電気的接続が直接行われます。
これらのスタックメモリはGPUとともにインターポーザ上に配置され、メモリと計算が別々の部品ではなく、一体化したシステムとして動作する高密度パッケージを形成します。
その結果、非常に広いデータ経路と短い電気的距離が組み合わさり、HBMの特徴である高帯域幅が実現されます。
なぜAIはHBMに依存するのか
AIのワークロード、特にモデルのトレーニングでは、大量のデータを継続的に動かす必要があり、数十億から数兆規模のパラメータが繰り返し読み書きされます。
そのため、大量のデータを高速に移動するための高帯域幅と、計算ユニットがデータ待ちで停止しないようにするための低レイテンシの両方が求められます。
- 高帯域幅により、大量データを高速に転送できる
- 低レイテンシにより、計算ユニットの稼働率を維持できる
従来のメモリアーキテクチャではこの両立が難しいため、HBMはハイエンドAIアクセラレータの標準的な構成要素となっています。
HBMがなければ、どれだけ高性能なGPUでも、処理よりもデータ待ちの時間が大きくなってしまいます。
トレードオフ:速度とコスト
HBMは大きな性能向上をもたらす一方で、そのスタック構造や高度なパッケージングにより、複雑さとコストも増加します。
複数のDRAM層、精密な接続、インターポーザ統合といった要素により、HBMは現在利用可能なメモリ技術の中でも高価な部類に入ります。
そのため、AIトレーニングやハイパフォーマンスコンピューティングのように、性能が最優先されコストが正当化できる用途に限って採用されることが一般的です。
コスト重視の一般用途システムでは、引き続き従来型のメモリが使われています。
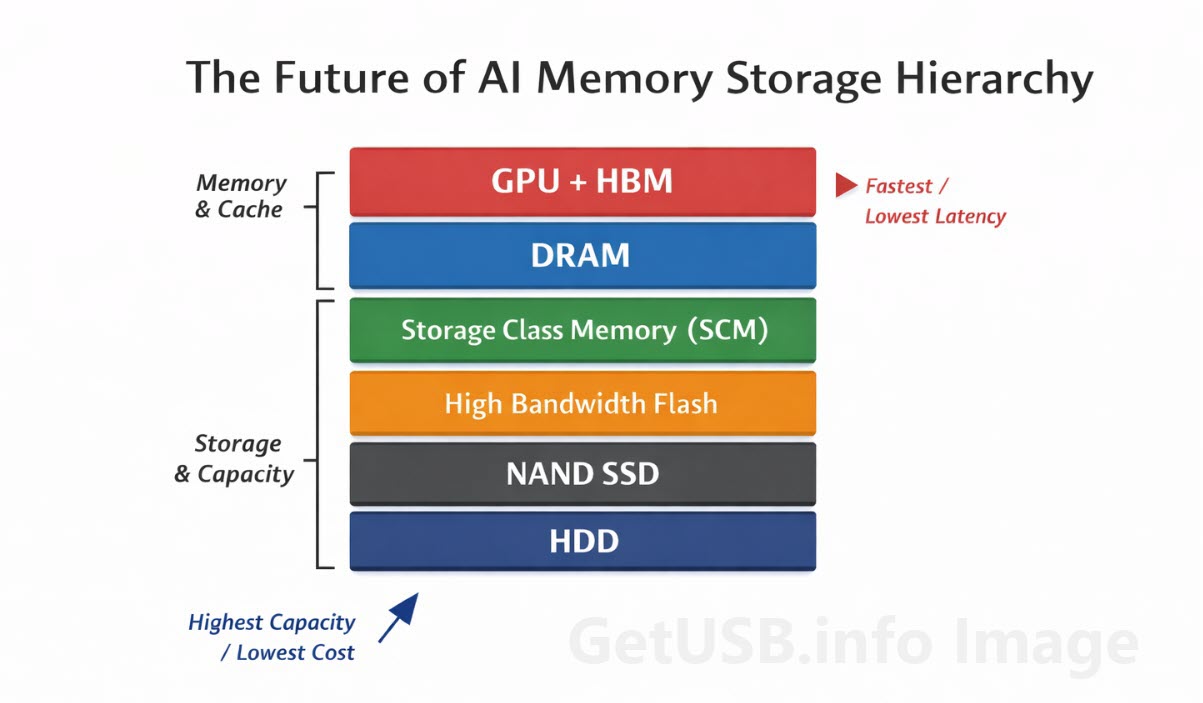
HBMの位置づけ
HBMは他のメモリを置き換えるものではなく、速度・コスト・容量のバランスに応じて最適化された階層型メモリ構造の最上位に位置づけられます。
| 技術 | 典型的レイテンシ | 帯域幅 | GBあたりコスト | 主な役割 |
|---|---|---|---|---|
| HBM(スタックDRAM) | ナノ秒 | テラバイト/秒 | 非常に高い | AIトレーニング用メモリ |
| DDR DRAM | 約100ns | 高い | 高い | システムメモリ |
| NVMe SSD | マイクロ秒〜ミリ秒 | 中程度 | 低い | 大容量ストレージ |
それぞれの層は性能・コスト・容量のトレードオフによって存在しており、すべてを同時に最適化できる単一の技術は存在しません。
HBMはその中でも最も高性能な層に位置し、コストよりも速度が優先される用途において不可欠な存在です。
変化
HBMは単に高速なメモリではなく、メモリを計算に物理的に近づけることで、現代コンピューティングの大きなボトルネックを解消する設計の変化と捉えるべきです。
AIシステムでは、データへのアクセスと処理速度が性能に直結するため、このアーキテクチャの変化は非常に重要な意味を持ちます。
最終的に、どれほど高度なプロセッサであっても安定したデータ供給に依存しており、その流れを改善することこそがHBMの価値です。
編集および画像に関する注記:本記事は、GetUSB.infoがメモリパッケージングおよびストレージハードウェアに関する編集リサーチと技術的理解に基づいて企画・監修しています。
画像について:本記事で使用している画像は実際のチップ写真をベースに、HBMの概念をわかりやすくするために補正を加えたものです。あくまで視覚的な説明を目的としたものであり、製造現場の正確な写真ではなく、現実に近いイメージ図として理解してください。
この記事の作成について:GetUSB.infoがテーマ設定、技術的な方向性、最終編集を担当し、AIツールは文章の流れや構成の補助として使用されました。全体を通して人による確認が行われています。