なぜDRAMだけでは、もはやAIに追いつけないのか

AIシステムが実際にどう作られているのかを見始めると、多くの人がごく自然にたどり着く結論があります。そして正直に言えば、それは最初の印象としてはとてももっともらしく聞こえます。
もしNANDがワークロードの一部にとって遅すぎて、しかも先進的なフラッシュアーキテクチャであっても無視できない程度の遅延を持ち込むのだとしたら、答えはもっとDRAMを増やすことだと思えてきます。DRAMは昔から高速な層だったからです。アクティブなデータが置かれる場所であり、応答も速く、そして何十年もの間、プロセッサが何かの到着を待って遊んでしまわないようにするときに頼るべき領域でした。
だからこそ、「速度が問題なら、手元で一番速いものを増やせばいい」という発想は簡単に生まれます。
その理屈は、AIが登場してDRAMを本来想定していなかった役割へ押し込み始めるまでは、かなりうまく成立しているように見えます。問題は、DRAMが突然遅くなったとか、時代遅れになったとか、以前より役に立たなくなったということではありません。問題は、AIワークロードがDRAMに対して、単なるcomputeとストレージの間の高速な作業層以上のことを求めている点にあります。
この変化の背景にある大きな流れについては、まずこのメインのピラー記事につながっています。NANDはなくならないが、AIサーバーはもはやフラッシュだけに依存していない です。
DRAMは速度のために作られたのであって、システム全体を背負うためではない
まず理解しておきたいのは、DRAMは昔から速度と応答性を中心に最適化されてきたのであって、大量のデータを大規模に抱え込むことを主目的にしていたわけではないということです。従来のコンピューティングでは、この違いが問題になることはほとんどありませんでした。多くのワークロードでは、アクティブなデータと保存データのあいだに比較的きれいな分離があったからです。システムはすぐ必要なものをメモリに置き、残りは必要に応じてストレージから引き出し、その受け渡しはたいていうまく機能していたので、深く意識されることもあまりありませんでした。
AIはそのバランスをかなり劇的に変えてしまいます。小さめのアクティブデータを処理して先へ進むのではなく、AIモデルは大規模データセットを何度も参照し、情報を並列に動かし、しかもワーキングセットのずっと大きな部分を長時間にわたってcompute層のすぐ届く範囲に置いておこうとします。つまり、DRAMはもはや現在のタスクだけを保持していればよい存在ではありません。システムが常に近くに置いておきたがる、巨大で絶えず変化するデータのかたまりを支える役目まで担わされているのです。
これはまったく別の仕事です。
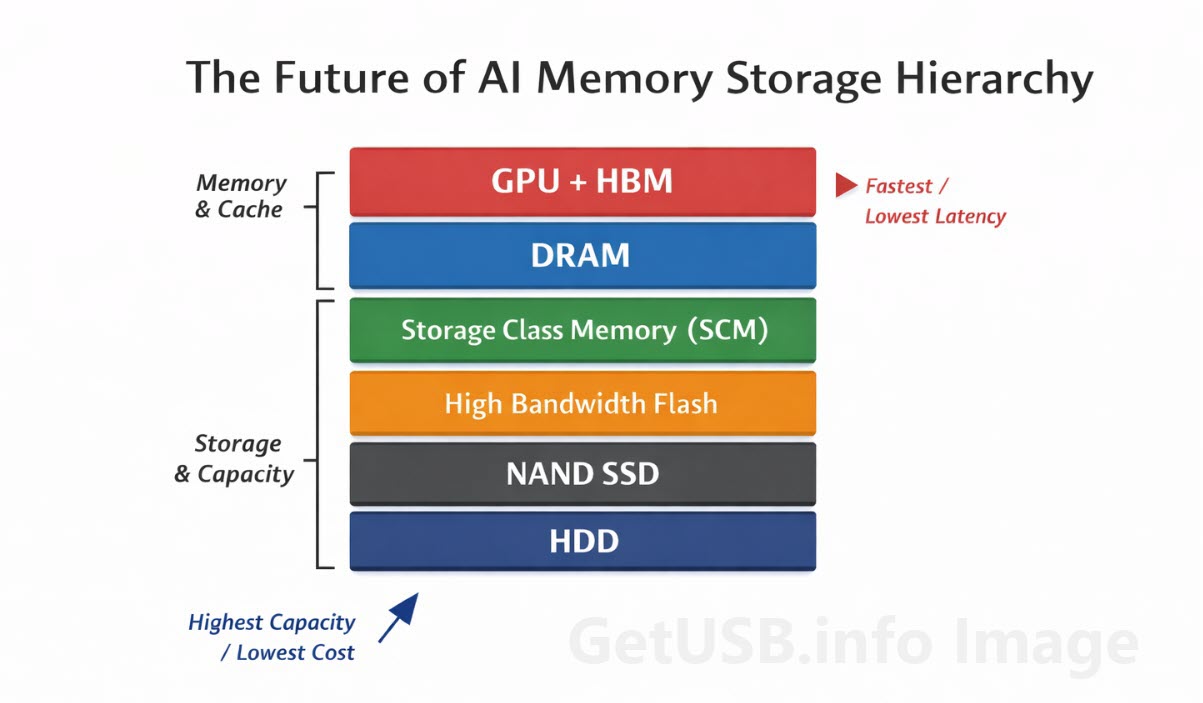
そして、だからこそDRAMの上や周辺にある技術がより重要になってきました。以前の記事である High Bandwidth Memory(HBM)とは何か、そしてなぜAIはこれに依存しているのか では、GPUが空腹にならないように、より少量の重要データをプロセッサの極めて近くへ置くことに焦点がありました。あの記事は「近さが重要だ」という点を示していますが、同時に次の問題も静かに浮かび上がらせています。ワーキングセットがその直近の層を超えて広がった瞬間、システムは残りすべてをどこに置くのかを決めなければならないからです。
最初の壁はコストであり、それはすぐに現れる
「DRAMを足せばいい」という考え方が好まれやすい理由のひとつは、それがすっきりしていて直接的に聞こえるからです。けれども現実には、これはあっという間に高コストになります。DRAMの価格感はNANDとはまったく違いますし、AI領域までシステムをスケールさせ始めると、単にサーバーへ少しだけメモリを増設する話では済みません。数百ギガバイト、場合によってはそれ以上を、複数のノード、ラック、クラスター全体にわたって扱うことになります。
そうなると、DRAMは性能向上のためのアップグレードというより、インフラ上の負担のように見え始めます。コスト曲線は緩やかには上がりません。かなり急な角度で上がっていくため、あらゆるデータ局所性の問題をDRAMだけで解決しようという発想は、その経済性そのものによって崩れ始めます。
メモリスタックが単純化するのではなく、むしろ深くなっている理由のひとつはそこにあります。業界がDRAMから離れつつあるのは、DRAMの価値が失われたからではありません。AI規模のレイテンシに敏感なあらゆる問題に対して、DRAMだけが答えになり得るという前提から離れつつあるのです。
次の壁は電力であり、この問題は眠らない
仮にコストを正当化しやすかったとしても、DRAMにはシステムがある程度の規模を超えると無視できなくなる別の問題があります。それが電力です。DRAMは状態を保持するために、常に通電されていなければなりません。これは技術の性質そのものです。つまり追加すればするほど、そこにデータを置いて待機させるだけで、システムはより多くのエネルギーを消費することになります。
小規模な環境なら、そのオーバーヘッドは受け入れられるように感じられるかもしれません。しかし高密度で継続稼働するAIシステムでは、それが大きな運用上の問題へと変わります。DRAMが増えるほど、消費電力は増え、発熱は増え、冷却負荷は増し、プラットフォーム全体の設計にもより強い圧力がかかります。すると判断基準は単なるメモリ容量ではなくなります。熱設計上の限界、データセンター効率、そしてこれほど大量のアクティブメモリを24時間365日生かし続けるコストを支えられるのか、という話になってくるのです。
ここで中間層の役割がより納得しやすくなってきます。前回の ストレージクラスメモリ解説:DRAMとNANDの間にある欠けた層 では、DRAMを置き換えるのではなく、より多くのデータをcomputeの近くに残しながらも、すべてを最も高価で電力を食う層へ押し込まないようにすることで、DRAMへの圧力を和らげるという考え方が語られていました。
さらに、近接性には物理的な現実がある
AIシステムでDRAMが無限にはうまくスケールしない理由はもうひとつあります。それは予算というより物理に関係しています。DRAMが価値を持つ理由のひとつは、プロセッサに比較的近い位置に置けることです。メモリがcomputeに近いほど、一般にレイテンシは低くなり、システム全体の反応も良くなります。しかし、その「近さ」は何の代償もなく永遠に拡張できるものではありません。
CPUやGPUの近くに置けるメモリ量には物理的な限界があります。配置の複雑さ、配線長、信号品質、パッケージング制約が、ある地点を超えると逆に不利に働き始めるからです。高度なメモリパッケージングが登場したのは、まさにこのためです。HBMが存在するのは、従来のDRAM配置には限界があるからです。そしてcompute側が十分に高速になると、それまで以上に距離や経路が効いてくるようになります。
とはいえ、HBMも容量面での完全な答えではありません。驚異的な帯域幅はありますが、無限の容量があるわけではないからです。そのためシステムは、極めて近くに置けるものと、離れた場所へ置かざるを得ないものとの間で、常にバランスを取ることになります。AIワークロードは、その綱渡りを従来システムよりはるかに強く引き伸ばしているのです。
AIは小さな遅延すら高くつかせる
AIインフラの興味深い点のひとつは、従来のワークロードではほとんど隠れていた非効率を露わにしてしまうことです。より伝統的なシステムであれば、データアクセスのわずかな遅れはそれほど大きな意味を持たないかもしれません。プロセッサが少し待ち、タスクが少し遅れて終わり、ユーザーは何も気づかない。それで済みます。ところがAIシステムは、非常に大きな並列性で動作し、しかもcompute層そのものに莫大なコストがかかっているため、そうした遅れに対してずっと厳しいのです。
GPUが必要なタイミングでデータを受け取れなければ、それは単なる技術的な煩わしさではありません。高価なアイドル時間です。それが並列に動く多数のアクセラレータ全体に広がれば、ごく小さな遅延であっても、実際の利用効率の損失として表れてきます。
すると目標そのものが変わります。目指すのは単に「速いメモリを持つこと」ではありません。システムの中で最も高価な部分を常に忙しくしておけるだけの規模で、データ供給を一貫して維持することです。これはずっと難しい要求であり、だからこそAIインフラがある程度を超えて大きくなると、DRAMだけでは足りなく見えてくるのです。

倉庫のたとえは今でも有効だ – ただし規模が大きくなっただけだ
これまでの記事と同じ倉庫のたとえを使い続けるなら、DRAMは今でも荷捌き場です。アクティブな仕事が行われ、荷物が開けられ、仕分けられ、すぐ使える状態へ移される場所です。長い間、このモデルはうまく機能していました。荷捌き場での活動量が管理可能で、システムもすべてを同時にそこへ並べておくことを要求していなかったからです。
AIはその運用規模を変えてしまいます。今や荷捌き場は、ほぼ絶え間ない物量の流れを支えなければならず、はるかに多くの処理が並列に進み、しかも遅延への許容度はずっと低くなっています。どれほど優れた荷捌き場であっても、ある地点を超えるとただ広げ続けることはできません。効率よく処理できる並列動作の数にも、置ける在庫にも、物理的なスペースにも限界があり、その先ではレイアウトそのものが問題の一部になってしまいます。
だから答えは、荷捌き場を無限に大きくすることではありません。答えは、その周囲のワークフロー自体を作り直すことです。
そこで初めて、メモリ階層のほかの層が意味を持ち始めます。HBMは最も時間に敏感なデータをプロセッサのすぐ隣に置きます。ストレージクラスメモリは、アクティブメモリとより遅いストレージの間の遷移を滑らかにします。そして、より新しい記事である フラッシュメモリはすべてを保存する – ただし、自分自身の歴史を除いて では、ストレージ側もまた、より賢くシステムへデータを供給できるように再設計されつつあることへ焦点が移っています。
それらの層は、DRAMが失敗したから存在しているわけではありません。AIが、「1つの高速な層だけで全ワークロードを支えられる」という考え方をすでに超えてしまったから存在しているのです。
これはAIメモリスタックにとって実際には何を意味するのか
ここで本当に重要なのは、DRAMが消えていくという話ではありません。そんなことは明らかに起きていません。DRAMは今でもスタック全体の中で最も重要な要素のひとつです。変わっているのは、その役割です。あらゆるアクティブデータが住むべき場所である、という立場から、最も緊急性が高く時間に敏感なデータが住む場所へと役割が変わりつつあり、規模、コスト、容量の増大する負担はほかの層が受け持つようになっています。
これは微妙な変化ですが、とても重要な変化です。つまりAIインフラは、以前の「メモリはこちら、ストレージはあちら」という単純な二層モデルから離れ、それぞれの技術が最も向いている部分のワークロードを担う、もっと複雑で繊細な構造へ移行しているということです。
簡単に言えば、DRAMは依然として不可欠ですが、それだけではもう足りません。AIはワーキングセットの大きさ、computeの速度、遅延のコスト、そしてすべてを近くに置いておくことの経済性を変えてしまいました。それらすべてが同時に変わった以上、メモリ階層もそれに合わせて変わらなければならないのです。
この先に何が来るのか
DRAMが、AIがcomputeの近くに置いておきたいすべてを抱え込めるほどには伸びないと受け入れた瞬間、次の問いはかなり明確になります。その残りのデータは実際にはどこに置かれるのか。しかも扱う情報量が、メモリ内に保持しておくにはあまりにも大きすぎる場合はなおさらです。
そこで議論は再び方向を変え、多くの人がすでに脇へ押しやられたと思っている技術が、驚くほど重要な形で再登場します。DRAMが規模の壁に苦しみ、フラッシュもまた独自のコストとレイテンシのトレードオフを抱えている一方で、ハードドライブは依然として、スタックのほかの部分では簡単に置き換えられないものを提供しているからです。それは、膨大なボリュームに対する実用的な容量です。
そして、まさにその理由から、このシリーズの次回では、なぜハードドライブが今でもAIインフラにとって重要なのかを見ていく必要があります。
著者について
この記事は、USB技術、フラッシュメモリの挙動、データストレージシステムにおいて20年以上の経験を持つ、GetUSB.infoの長年の寄稿者 Greg Morris の指揮のもとで作成されました。ここで示されている視点は、実際の業界経験に根ざした知見と、AIインフラを含む進化するワークロードの中で現実のシステムがどう振る舞うかについての継続的な分析を反映したものです。
この記事の作成方法
この記事の概念、構成、技術的な方向性は、人間の専門家によって執筆・確認されました。AIツールは、複雑な考え方をより自然な流れの文章へ整理するために、リズム、流れ、読みやすさの補助として使われていますが、根本にある技術的な正確性や意図そのものは変えていません。
ビジュアルについて
この記事で使用している画像は、データフローのボトルネック、メモリ階層の挙動、システムレベルの非効率といった、従来のストックフォトでは表現しにくい概念を説明するために специально作成されたものです。これらのビジュアルは、技術的な説明を補強し、読者にとっての理解をより明確にすることを目的としています。